In 'The Misbehaviour of Markets', Benoit Mandelbrot mentions Zipf's Law - which describes the frequency distribution of word usage in a text. Zipf's Law is a power law, and a Mandelbrot customization of Zipf's original law bears the name of both - the Zipf-Mandelbrot Law.
Now, to empirically determine the distribution, we use a plain-text version of the King-James Bible.
The python code below features methods that
- open the as-formatted king james, and parse it to a list of text lines
- fragment a list of text lines to a [list] sequence of words, by splitting on punctuation and white-space
- sieve a word sequence to a word frequency distribution dictionary
from time import time
SOURCE_FILE_PATH = 'f:/kjv12_no_header.txt'
DEST_FILE_PATH = 'f:/dist.txt'
from time import time
def p(s):
print(s.strip())
def extract_text_from_file(path):
'''
parse king james bible text located at file path 'path'
strip out all info except for raw text lines, without
verse/verse number annotations
returns list of text lines
'''
book_count = 0
line_count = 0
text_lines = []
try:
f = open(path, 'r')
completed = False
i = 0
start_time = time()
line = ''
while completed == False:
line = f.readline()
i = i + 1
if (line == None) or (line == ''):
completed = True
continue
if len(line) < 8:
continue
# BOOK
# Book 01 Genesis
if line[:4] == 'Book':
book_count += 1
line = line.strip()
splut = line.split('\t')
book_num_str = splut[0].split(' ')[1]
book_num = int(book_num_str)
book_name = splut[1]
continue
# INIT VERSE LINE
# 001:002 And the earth was without form, and void; and darkness was
if line[3] == ':':
verse_book_num = int(line[0:3])
verse_num = int(line[4:7])
text = line[8:len(line)-1]
text_lines.append(text)
line_count += 1
continue
# SUBSEQUENT VERSE LINE
# upon the face of the deep. And the Spirit of God moved upon
if line[:8] == ' ':
text = line[8:len(line)-1]
text_lines.append(text)
line_count += 1
continue
end_time = time()
duration = end_time - start_time
print('file load process took %s seconds' % duration)
finally:
f.close()
return text_lines
def fragment_text_to_word_sequence(text):
'''
expects text = list of lines of punctuated text
returns string list corresponding to the word_sequence of the text
'''
word_sequence = []
init_punc_split_chars = [ ',', '.', '\"', ':', ';', '!', '(', ')', ' ', '?']
start_time = time()
for line in text:
split_chars = init_punc_split_chars
current = [line]
for split_char in split_chars:
next = []
for piece in current:
for fragment in piece.split(split_char):
if fragment != '':
next.append(fragment)
current = next
word_sequence.extend(current)
end_time = time()
duration = end_time - start_time
print('split to word sequence took %s seconds' % duration)
return word_sequence
def build_word_dist_for_sequence(word_seq):
'''
construct word frequency distribution for given word sequence
'''
freqs = {}
keys = []
start_time = time()
for word in word_seq:
word = word.lower()
if word in keys:
freqs[word] += 1
else:
freqs[word] = 1
keys.append(word)
end_time = time()
duration = end_time - start_time
print('sieving of word sequence to frequency distribution took %s seconds' % duration)
return freqs
def write_word_freqs_to_disc(freqs):
dest = open(DEST_FILE_PATH, 'w')
sorted_list = sorted(freqs.items(), key = lambda x : x[1])
sorted_list.reverse()
for key,value in sorted_list:
s = str(key) + ',' + str(value) + '\n'
dest.write(s)
dest.close()
def main():
text = extract_text_from_file(SOURCE_FILE_PATH)
word_seq = fragment_text_to_word_sequence(text)
freqs = build_word_dist_for_sequence(word_seq)
write_word_freqs_to_disc(freqs)
if __name__ == '__main__':
main()
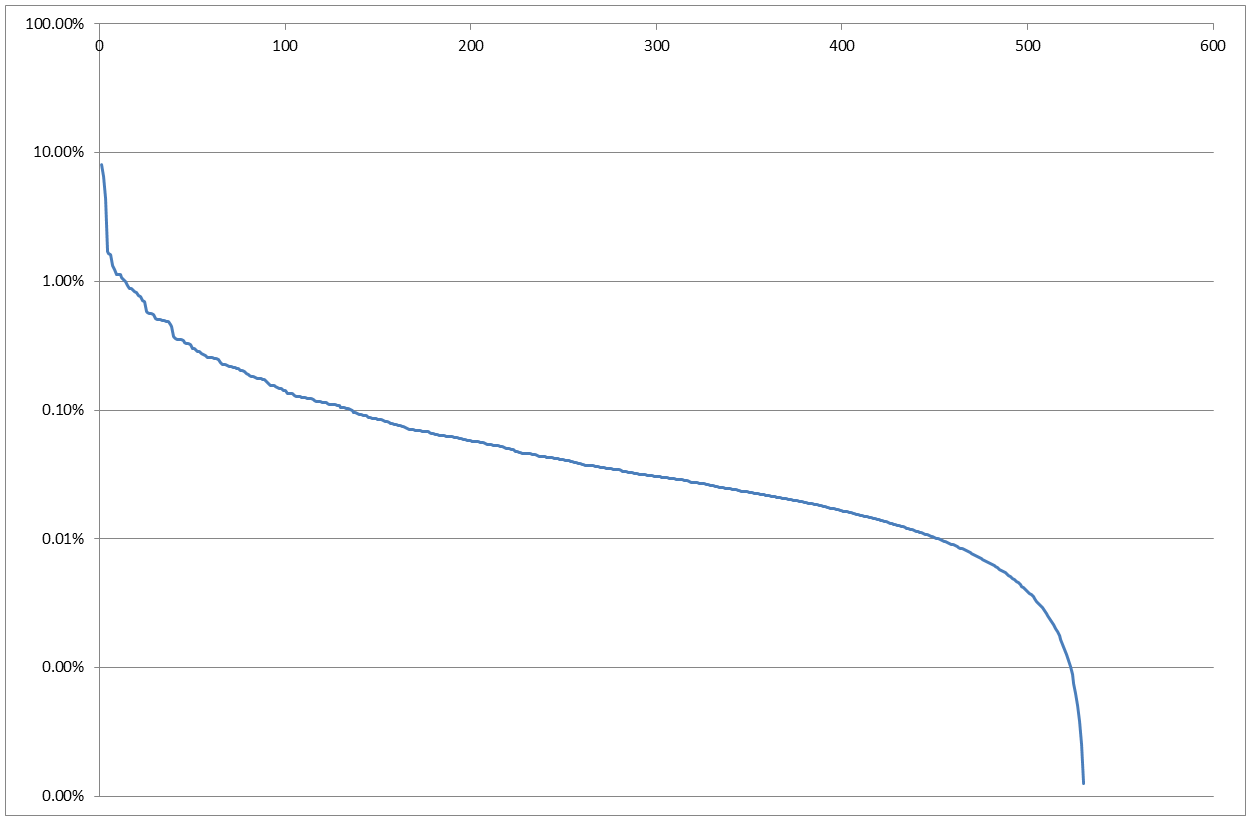
These results...The Top 25 Words


No comments:
Post a Comment
comment: